Introduction
A relational database consists of more than one table, which are linked together by certain fields.
Where these fields are linked, this is called a relationship. This allows us to organise our data more efficiently.
In this lesson, we will learn about:
- Database relations
- Relational keys
- Integrity constraints
- Entity relationships

Database Relations
An entity relationship is a link between two tables. It is created by having matching attributes in each table.
Within entity relationships, we commonly model the relations between two tables as being either generic or semantic.
Generic entity relationships take a more general and non-specific view of the relationship.
They are more concerned with which entities are related to help you understand the overall structure of the database.
Semantic entity relationships incorporate more of the entities’ actual attributes and show the primary and foreign key attributes that create the relationship between the tables.

Relational Keys
Relationships between two tables are created through matching fields that appear in both tables.
These fields are known as the relational keys, and there are a few different kinds of keys:
- Super Key
- Candidate Key
- Primary Key
- Foreign Key
- Composite Key
Let’s look at each of these in more detail.

Relational Keys
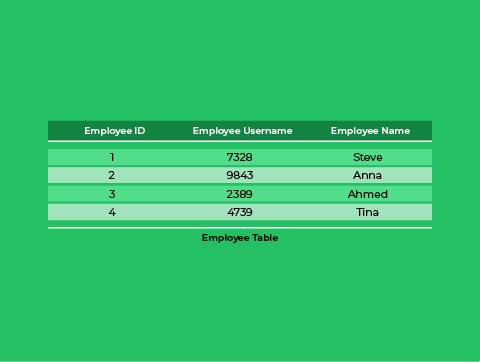
We’ll use the example table on the right to demonstrate these keys.
Super Key
This is any attribute, or groups of attributes, that can uniquely identify a tuple in a relation. In our example, the following attributes or groups of attributes are super keys.
- {EmployeeID}
- {EmployeeUsername}
- {EmployeeID, EmployeeUsername }
- {EmployeeID, EmployeeName}
- {EmployeeUsername, EmployeeName}
- {EmployeeID, EmployeeUsername, EmployeeName}
Relational Keys
Candidate Key
This is a super key that has no super key subsets. So, the smallest subset of super key attributes. In the table above, the following super keys are also candidate keys.
- {EmployeeID}
- {EmployeeUsername}
Primary Key
This candidate key has been selected to be the unique identifier of each tuple in a relation.
We would choose one of the candidate keys above, EmployeeID or EmployeeUsername, as our primary key.
Relational Keys
Foreign Key
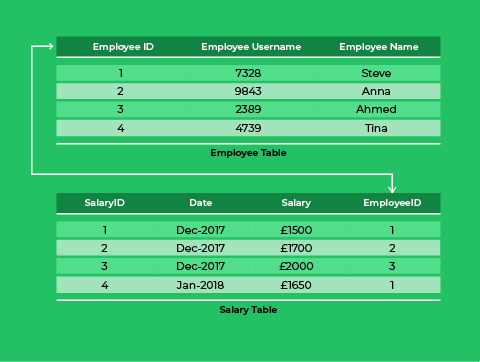
This is an attribute of a table that is also a primary key in another table. This establishes a link, or relationship, between these two tables.
In our example on the right, the EmployeeID attribute in the salary table establishes the relationship with the EmployeeID primary key attribute in the employee table.
Composite Key
This is a combination of two fields that together can uniquely identify a record. This can be used as an alternative to a primary key.
Integrity Constraints
Integrity constraints are used to ensure the accuracy and consistency of data in your relational database. The main two types of integrity constraints are:
Entity Integrity
This rule states that every entity (table) must have a primary key field, and the data in that primary key field must be unique to each record.
Referential Integrity
This rule states that every foreign key value must match the primary key value of a record in another table or be null.
We’ll learn more about referential integrity in the lesson “The Role of Normalisation”.

Entity Relationships
We saw earlier that an entity relationship is the link between two tables and is created by having matching attributes in each of the two tables.
There are three different types of entity relationships that we can have:
- One-to-one
- One-to-many
- Many-to-many
Let’s look at each of these in more detail.

Entity Relationships
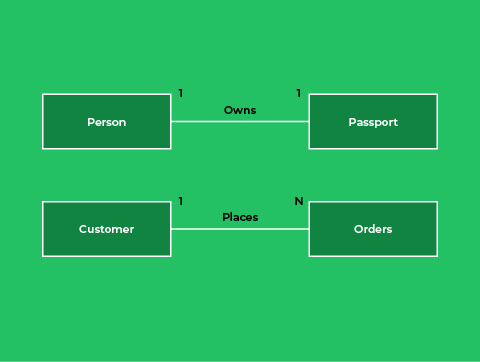
One-to-One
This is where a single record of a table is related to a single record of another table. This could be the relationship between a person and their passport. This is illustrated below:

One-to-Many
This is where a single record of a table is related to more than one record in another table. The foreign key would appear in the many side of the relationship. This could be the relationship between a customer and their orders. This is illustrated below:
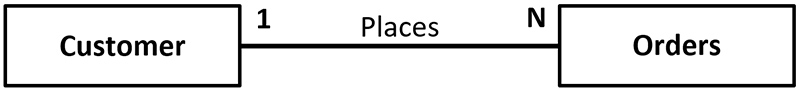
Entity Relationships
Many-to-Many
This is where more than one record of a table is related to more than one record of another table. This could be the relationship between students and their courses. This is illustrated below:
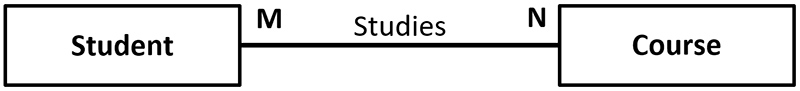

Entity Relationships
Unfortunately, a relational database cannot represent many-to-many relationships. Where a many-to-many relationship exists, we must resolve it into two one-to-many relationships.
For example, the student-course relationship can be resolved as:
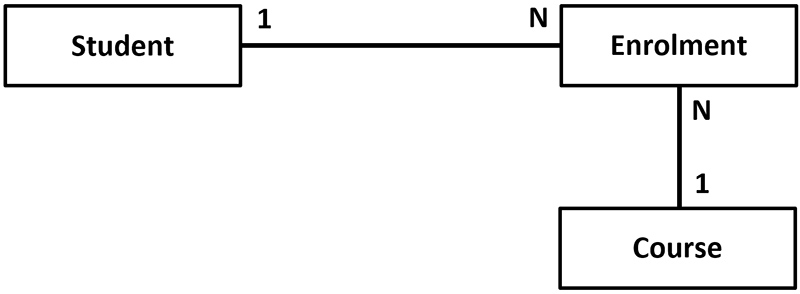
By far, the most common form of entity relationship is the one-to-many relationship.
Lesson Summary
An entity relationship is a link between two tables. It is created by having matching attributes in each table.
A super key is any attribute(s) that can uniquely identify a tuple in a relation. A candidate key is a super key that has no subsets.
A primary key is a candidate key selected as the unique identifier of each tuple in the relation. A foreign key is an attribute of a table that is also a primary key in another table.
A composite key is a combination of two fields that together can uniquely identify a record.
Integrity constraints are used to ensure the accuracy & consistency of data in your relational database.
Database relationships can be one-to-one, one-to-many or many-to-many.
