Introduction
Once a problem has been decomposed into smaller tasks and any patterns identified, it is useful to examine it, identify what is actually required, and remove any unnecessary elements.
This will help the programmer save time in developing the solution. This process is called Abstraction.
In this lesson, we’ll learn about the process of abstraction:
- Identifying and remove information from a problem
- Creating abstraction layers
- Defining abstraction layers

Removing Information From a Problem
Once we know what the problem is, we can then start to take steps to identify what data & information is require and what the program needs to do.
For example, looking at the Information Management System from the previous lesson, we know that the program will need to:
- Allow a teacher to record student attendance
- Produce reports for staff on student attendance
- Produce reports for parents on the attendance of their son or daughter
From this, we can identify the information required will include:
- Attendance data
- The ability to search by surname, date and subject

Removing Information From a Problem
At this stage, we can also start to filter out any data or information that is not necessary.
If we do not, then there is a real risk that any programmer will attempt to include this information in the programmed solution. This will waste time and money.
One requirement of the IMS is that a teacher can look up attendance details about a specific student.
To do this, they type the student’s surname, click ‘enter’ and information is displayed.
The information needed will be surname only.
Removing Information From a Problem
This will give us a list of students with the specified surname, but the information brought back may include their first, middle, and last name(s), subject, attendance data, and lesson date and time.
Information not needed is gender, age and date of birth as this is not relevant to the search request.
Creating Abstraction Layers
Abstraction means hiding the complexity of something away from the thing that is going to be using it.
For example, when you press the power button on your computer, do you know what is going on?
Of course not – your computer just turns itself on. That’s all you need to know.
The process of powering up your computer and starting the load process of the Operating System into RAM memory from the boot sector has been hidden from you.

Creating Abstraction Layers
Abstraction in computational thinking is a technique where we split individual parts of the program down into imaginary ‘black boxes’ that carry out operations.
We don’t care HOW the operations are carried out, only that they work consistently and accurately.
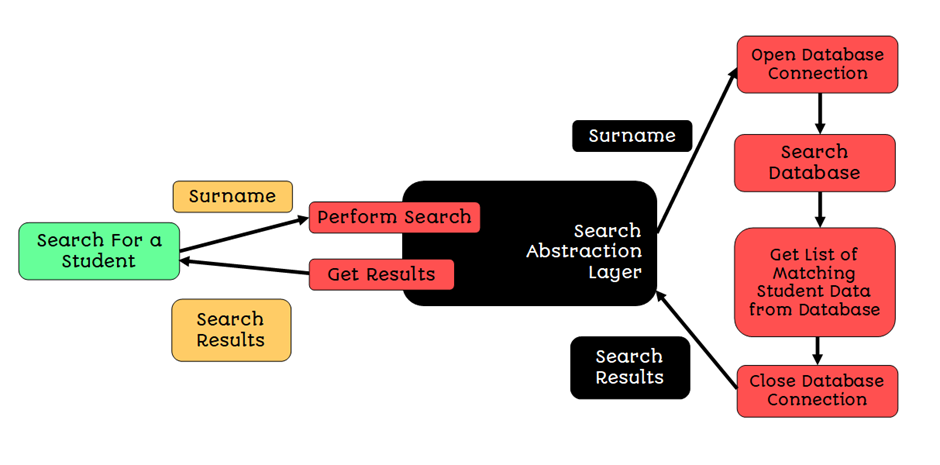
For example, in our IMS, there will be a ‘search for a student’ process that uses the Search Abstraction Layer.
The Search Abstraction Layer contains all the functionality to:
- Connect to a database
- Search the database
- Get the results back from the database
- Close the connection to the database
Creating Abstraction Layers
Creating Abstraction Layers
The ‘Search for a Student’ process does not know that the Search Abstraction Layer opens a connection to a database and gets a list of search results; all it knows is that it gives the black box a surname and gets back some results.
This is Abstraction: the student search functionality is hidden away from the rest of the system.
Defining Abstraction Layers
Once an abstraction layer has been identified, it can be fully described by its:
- Inputs – the values entered into the layer
- Outputs – information produced by the layer
- Variables – values that will change between each use of the layer
- Constants – values likely to remain fixed between each use of the layer
- Processes –functions that the layer will carry out
- Repeated Processes – functions that happen multiple times within the layer
This is called defining the Abstraction Layer.

Defining Abstraction Layers
Consider the student search system, it can be represented using the following terms:
- Inputs –the student’s surname
- Outputs – a list of students with a matching first, middle and last name(s), subject, attendance data and the lesson date and time.
- Variables – the surname of a student used for searching.
- Constants – the name and IP address of the database that contains the student data.
- Key Processes – opening and closing database connections and searching the database for a given student surname.
- Repeated Processes – adding students with matching surnames to the list of students.
Lesson Summary
Abstraction is hiding the complexities of one part of a computer program from another.
Abstraction is where we identify the information needed to solve a problem.
Abstraction is where we filter out unnecessary details at different stages of solving the problem.
Abstraction Layers are where we group areas of functionality.
We define Abstraction Layers by including variables, constants, key processes, repeated processes, inputs and outputs.
